Hank Heijink
[Published as: Heijink, H. (1996) Matching Scores and Performances. Master's thesis, Nijmegen University]
2. Scores, Performances And Matches
There are a lot of things about human consciousness we don't understand. One of those things is how we experience music and how we perform music. One way to try to understand this is to model human behaviour with a computer. By analyzing and creating expression in music with the help of a computer, we can hope to gain insight in the thought processes of a music listener or performer.
In the analysis of expression in music performance, score information has to be copied to a performance, for example when the timing of structural units (like bars, voices or phrases) is studied. In a performance the number of notes and the order in which they are played are not fully specified by the score. For instance, a chord, a parallel structure of notes, may be given a distinct timbral quality by playing some of its notes ahead of others, in some pieces the melody and accompaniment may be played slightly out of phase, and, as a last example, a trill has an unspecified number of notes. The matching of score and performance data becomes even more difficult when errors are made by the performer.
The area of score and performance matching has received quite some attention from the field of electronic music. Composers were looking for a so-called score follower to enable a computer to accompany a soloist[1], but no fully operational robust methods have emerged. Other research areas have led to the development of so-called matchers, but neither have they led to completely satisfiable solutions.
In this report, I have tried to give an overview of the solutions found to date and to propose a matcher that makes use of the structure of a piece to match. When I started the research that led to this report, the goal was to come up with a working CLOS program that could be integrated in POCO, a system that can be used to analyze expression in musical performance. Six months later, it is apparent that that goal was too ambitious, and so I don't have a working program, but a formal specification.
I would like to thank my supervisors Peter Desain, Henkjan Honing and Huub van Thienen for their patience, encouragement and indispensable help. Furthermore I would like to thank Mr. Ed Large for helping me to get the details of the tabular matcher clear, and finally anyone who made suggestions on the way. Without them, this report would not have been written.
This report is the end product of a six month's graduation assignment, which was carried out at the Nijmegen Institute of Cognition and Information (NICI) under the supervision of Peter Desain (NICI), Henkjan Honing (University of Amsterdam) and Huub van Thienen (University of Nijmegen).
Being a student of both computer science at the university of Nijmegen and classical guitar at the conservatory of Tilburg, I was very lucky to find a research project which combined my two interests: music and computer science. After a couple of meetings with Peter Desain and Henkjan Honing, we decided that I would concern myself with the matching of scores and performances.
A score is a copy of a composition with parts on series of staves[2], but I will use the term to refer to a computer representation of a score as well.
A performance is the act of playing the music written in the score. Again, I will also use the term `performance' to refer to a computer representation of a `real' performance. Exact definitions of scores, performances and matches will be given in sections 1.4 and 3.2.
This research turned out to be far more difficult and challenging than I at first thought. There is not much literature on the subject and every attempt to solve the problem has its weak points. The definition of the problem is not clear (to say the least) and so, there are no set criteria to judge the merit of the proposed solutions.
I have attempted to classify the different kinds of possible solutions to the matching problem and examined some examples of those solutions. Three matchers I have examined in detail and compared their behaviour on example scores and performances. The first two matchers are existing ones, the third one is my attempt to combine the strong points of various matchers and propose another possible solution to the matching problem.
In this chapter I will put the research in perspective by describing the research institute NICI, and POCO, a system developed by Peter Desain and Henkjan Honing, to which an implementation of the structure matcher should be a contribution.
NICI is short for Nijmegen Institute for Cognition and Information. The institute has five divisions: computational psycholinguistics and artificial intelligence, motor function and rehabilitation, mathematical models and decision theory, cognitive neuroscience, and perception (see NICI, not published).
One line of research in the division of Perception is the perception and the playing of music. What effects does musical expression have on the perception of a musical performance?
Expression is what makes the difference between a sequence of played notes and music. Expression gives the music its mood, its feeling, and it is the one thing that distinguishes a good performance from a bad performance. Expression lines out the structure of the music, making it easier for the listener to understand. Expression is the means to build up or release tension in a performance. An expressive performance is literally an interpretation of a piece of music, it is a statement by the performer: `this is how I understand it.' Performing music is like telling a story, but there are as many stories in a piece of music as there are performers of it. In short, expression is hard to capture (Desain & Honing, 1992, pp. 25-40).
The above description of expression--somewhat lyrical and certainly very vague--is not of much use to scientists who want to study expression in music, but there is no simple and evidently correct definition of expression. Expression is, however, most apparent in three aspects of music: timing, dynamics and articulation. It is a very complicated matter, and it takes years of study to become a musician, i.e. to know how and when to use what kind of expression. One of the reasons is that normally the aspects mentioned above are used simultaneously and very subtly.
The research mentioned above tries to provide a deeper understanding of expression. It concentrates on three perspectives: musicological aspects (what are the rules of expression in different kinds of music), cognitive aspects (how does a good performance or interpretation facilitate the understanding of the music by the listener), and computational aspects (the design of appropriate data structures and the development of programs dealing with expression).
Computers are indispensable in the research, because they can be used to drive a synthesizer. The computer can then record a performance and play back that performance in exactly the same way, or can be instructed to alter some aspects of expression in that performance.
A large collection of computer programs have been developed to assist in this process; among these tools is a workbench named POCO.
POCO has been developed by Peter Desain and Henkjan Honing as part of research on the modeling of expression in musical performance (Honing, 1990). It consists of a collection of tools that can be used for the analysis, modification and generation of expression in music, built around a consistent and flexible representation of musical objects.
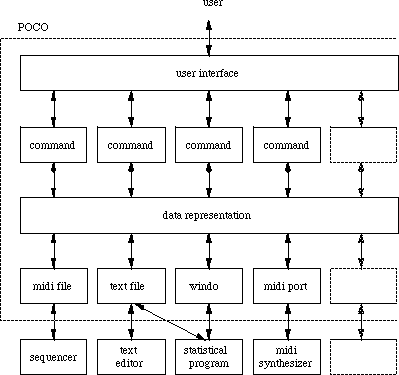
Figure 1.1 illustrates the structure of POCO. The heart of POCO is the data representation: all the commands and transformations are built round it. All commands (e.g. a command to change the tempo of a piece, or a command to match a score with a performance) operate via the same user interface and on the same data representation.
Figure 1.1: the structure of POCO
Furthermore, a piece of music (a score, or a performance), can be transformed from POCO's own representation to other representations such as MIDI files, text files, etc., which can then be used in other programs (sequencers, text editors, and many others). POCO has been constructed in such a way that more commands and representation transformations can be added according to the user's needs.
The purpose of POCO is to assist in analyzing and modifying expression in music. To give the reader a clearer idea of what POCO is supposed to be, I will list some of the demands an ideal system should meet (Honing, 1990).
These are but a few of the tasks such a system should be able to perform. Of course, POCO cannot do it all, but it is a good step on the way. Fortunately, POCO is designed in such a way that it is easily extendible. One of the tasks that POCO can perform is mutually adjusting the performance and the score (matching the performance with the score): this is the task on which I will focus throughout this report.
A matcher is an algorithm that takes a score and a performance as input and identifies which performance notes correspond with which score notes. A match is therefore a set of pairs of notes, where the first component of the pair is a score note and the second component is a performance note (a match will be formally defined in section 2.5).
A matcher is necessary when one wants to study certain aspects of a performance that are related to the structure of a piece of music. For instance, phrases are structural components of a piece of music, and expression is highly dependent on the phrase structure. In this case, we would need to copy the phrase structure from the score to the performance, which can be done by a matcher or by hand.
Not only should a matcher be able to copy the structure from a score to a performance, it should also be able to cope with performance errors, i.e. it should not `get confused' if an error has been made, but be able to tell whether a score note has been left out, or an spurious note has been inserted, and continue its work.
Finally, a matcher should be able to recognize and handle score annotations like `trill' and `glissando'. These are non-trivial problems: a trill has an unspecified number of notes and a Baroque trill is played differently from a `modern' trill, so more information is needed. In a glissando, only the first and the last note are fixed, as a rule; what happens between them is not clear, that depends for a large part on the instrument in question.
The problems concerning the tasks of a matcher I have sketched above are only partly solved. Copying the structure information of a score to a performance is a trivial task, once all note correspondences have been established, so I won't treat it in this report, but concentrate on the actual matching (i.e. finding the note correspondences).
Certain types of score-performance combinations can make this very difficult, even when the performance is a `perfect'[3] one. There are lots of ways to handle errors in a performance, but no obvious winner presents itself; all methods are compromises between complexity and accuracy. I will discuss various methods in this report and I will say more about handling trills and glissandi in chapter 8.
In this chapter, we will formally define the notion of score, performance, match and matcher. Normally, a score is a prescription of a performance, usually written down on paper, while a performance is the act of playing the music written in the score. In this report, a score remains a prescription of a performance, but a performance is, instead of the act of playing music, the representation of the act of playing music, and hence written down, like a score.
Note that POCO handles a lot of things in quite a different way, or in a more complex way. It would not be practical to define scores and performances like POCO does, because of all the details that are important to other things than the matching problem.
A note is a written sign representing pitch and duration of a musical sound, while a tone is a musical sound. Therefore, a score is collection of notes and a performance (in the normal sense of the word) is a collection of tones. A performance in the sense of this report is not a collection of tones, rather a collection of representations of tones.
From this point on, a performance will refer to a collection of representations of tones. We will call the notes in the score score notes, and the representations of tones in the performance performance notes.
Definition 2.1 (Score note) A score note is an element of {0,...,127} .Q+.Q+.[0,1] (Q+ being defined as {x in Q |x >= 0}). Let (p, a, d, v) be a score note. Then p represents the pitch, a the onset, d the duration and v the velocity of the note.
The MIDI protocol demands that the pitch be a natural number in the set 0,...,127, but the algorithms described in this report do none of them need this restriction. However, in this report the notes will be referred to by name, rather than by number, according to the MIDI convention that note number 60 is c3.
The onset of a score note is a point in abstract time, at which the tone represented by the note should begin to sound. Onsets are not given in everyday scores, but they can be easily computed out of the durations: the score starts at 0, and if the first note has a duration of 1/2, the onset of the second note is 1/2, and so on. For the sake of simplicity, we will assume the presence of onsets, rather than computing them when needed.
In a score, the duration is symbolic: one duration value is chosen as a reference point, and all others are relative to that value. In many cases, the quarter note is chosen as the reference (e.g. equal to 1); a sixteenth note, for instance, would then be equal to 1/4, and a half note would be equal to 2.
The velocity attribute of a note stems from the MIDI protocol, which was designed to record music played on keyboard instruments. The velocity with which the key was depressed was also recorded, to be able to compute the loudness of the resulting tone. Hence the velocity attribute, a real number between 0 and 1.
For a score note, this attribute is perhaps less useful than for a performance note. Usually, in a sheet music score, only crude directions are given to the performer about the loudness asked for, like `softly' or `very strongly'[4].
Definition 2.2 (Performance note) A performance note is an element of the set {0,...,127} .R+.R+.[0,1] (R+ is defined analogously to Q+ ). Let (p, a, d, v) be a performance note. Then p represents the pitch, a the onset, d the duration and v the velocity of the note.
The difference between score and performance notes is in the onset and duration attributes. Performance notes, have their onset and duration attributes given in seconds. The duration of a performance note will also be referred to as sounding time. Another important notion is inter-onset time, which is the time between two consecutive onsets.
In a score, the duration and the inter-onset time are (by definition) always pairwise equal, while in a performance the sounding time will frequently be shorter than the inter-onset time.
In chapters 4, 5 and 6 I will treat score notes like performance notes, i.e. with real numbers for duration and onset. The reason for this is to be able to use the same data type for both types of notes, but it has no further consequences.
Definition 2.3 (Rest) A rest is an element of the set Q+.Q+. Let (a, d )be a rest. Then a represents the onset, and d represents the duration.
Rests can only appear in the score[5]
and they are not essential to the matching process. They can be
erased from the score before the match, and reinserted afterwards;
they can even be inserted into the performance after the match.
Because of this, in all algorithms in this report, we will assume
there are no rests in the score.
A score, as well as a performance consists of musical objects. The basic musical objects are notes and rests, the so-called simple objects (see figure 2.1). A note is a written sign representing pitch and duration of a musical sound, while a rest is a written sign representing the duration of a pause.
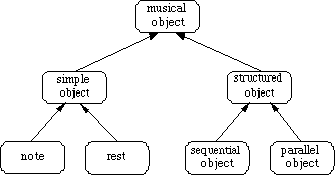
Figure 2.1: The hierarchy of musical objects
Musical objects can, in addition to simple objects, be structured objects. A structured object is a list of musical objects that are related to each other in a particular way. In this report we will restrict ourselves to sequential and parallel objects (trills and glissandi, among others, being structured objects as well).
We will now formally define musical objects and their relations.
Definition 2.4 (Musical object) A musical object is either a structured object or a simple object.
Definition 2.5 (Simple object) A simple object is either a note or a rest.
Definition 2.6 (Structured object) A structured object is either a sequential object, or a parallel object.
Ô
Definition 2.7 (Sequential object) A sequential object is a list of musical objects x0,...xn-1 such that:
Ô
Definition 2.8 (Parallel object) A parallel object is a list of musical objects x0,...xn-1, of which the following holds:
A parallel object containing only notes will also be called a chord. For the sake of simplicity[6], we have made use of a `stripped' version of the scheme in figure 2.1. The scheme we actually used is shown in figure 2.2. This leads to a slightly different version of a musical object:
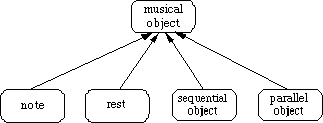
Figure 2.2: A `stripped' hierarchy of musical objects
Ô
Definition 2.9 (Musical object) A musical object is a note, a sequential object, or a parallel object.
The definitions for simple objects, structured objects and rests (rests are to be defined later) are not needed, and the other definitions (notes, sequential objects and parallel objects) remain the same. The reason for deleting the rests is given in the previous section, the extra level of abstraction is deleted--again--for clarity and simplicity.
A score is a copy of a composition with parts on series of staves. That is, in the `normal' sense of the word. A computer representation of a score (computer score, in short) is something entirely different, namely:
Definition 2.10 (Computer score) A computer score is a musical object (musical objects having been defined in the previous section).
We will use the term `paper score' for scores in the normal sense of the word, to avoid confusion with computer scores. When there is no danger of confusion, we will simply use the term `score'. An example of a paper score is given in figure 2.3. A computer score of the same excerpt is given in figure 2.4.
Figure 2.3: Example of a score
sequential(
(eflat4, 0, 1/2, 0.5)
(f4, 1/2, 1/4, 0.5)
(g4, 3/4, 1/4, 0.5)
(f4, 1, 1/2, 0.5)
(eflat4, 1 1/2, 1/2, 0.5)
(d4, 2, 1/2, 0.5)
(c4, 2 1/2, 1/2, 0.5)
(b3, 3, 3, 0.5))
Figure 2.4: A computer score
A live performance is the act of playing the music represented by
a score. A computer performance is a somewhat simplified[7]
representation of a live performance.
Ô
Definition 2.11 (Computer performance) A computer performance is a list of notes x0,...xn-1, such that
We will also refer to the list of notes representing a performance as a note-list. The definition of a score list (section 3.2.3) is also equal to this one.
Definition 2.12 (Match) A match of a score S and a performance P is a set M of pairs of notes, that meets the following demands:
A note s0 precedes a note s1 if onset (s0) < onset (s1), and there is a sequential object Seq in the score, such that both s0 and s1 are elements of Seq or of different elements of Seq (cf. chapter 6, the function precedes).
An example will clarify what `s0 precedes s1' means. Consider the following computer score:
parallel(
sequential(
(a3, 0, 1, 0.5)
(b3, 1, 1, 0.5))
sequential(
(c4, 0, 1, 0.5)
(d4, 1, 1, 0.5)))
Then (a3, 0, 1, 0.5) precedes (b3, 1, 1, 0.5) and the note (c4, 0,
1, 0.5) precedes (d4, 1, 1, 0.5), but (a3, 0, 1, 0.5) does not
precede (d4, 1, 1, 0.5), because they are not part of the same
sequential object.
Ô
Definition 2.13 (Maximal match) If M is a match, then M is a maximal match, if there are no two notes n0 and n1 such that M unified with {(n0, n1)} is still a match.
Definition 2.14 (Maximum match) M is a maximum match, if there is no other match M0 such that M0 has more elements than M.
By definition, every maximum match is a maximal match, but a
maximal match is not necessarily a maximum match.
Ô
Definition 2.15 (Matcher) An algorithm match is a matcher if it takes a score S and a performance P as its input, and produces a match M of score S and performance P .
Analogously to this last definition we can define a maximal matcher (producing a maximal match) and a maximum matcher (producing a maximum match). Every matcher discussed in this report strives to produce a maximum match, but as we shall see, this goal is not easy to attain.
In this chapter the matching process will be introduced by making a classification of different kinds of matchers. We will discuss three ways of dividing matchers into different groups: one can divide them by having or not hav- ing real-time constraints imposed on them (section 3.1), by the way they represent the score (section 3.2), or by the way they compare notes (section 3.3).
We will look at examples of different kinds of existing matchers and a new matcher will be introduced, which uses the temporal structure present in the score to match the notes. In the following chapters three matchers will be highlighted and we will compare their behaviour on example scores and performances. The first two are existing matchers, the third is proposed by the author of this report.
The design and behaviour of a matcher depends greatly on the task it is to perform. All matchers have the task of pairing score and performance notes in common, but there are roughly two very different goals to the matching process. One is the possibility to analyze aspects of a performance, another is accompanying a soloist playing from a score, or even an improvising soloist (see Dannenberg, 1984 and Dannenberg & Mont-Reynaud, 1987).
The matchers described in chapters 4, 5 and 6 are all written in a research context, to be able to study aspects of a performance. I will refer to these algorithms as non real-time matchers, as opposed to real-time matchers. Non real-time matchers have in common that they do not have any time constraints on the finding of a match, they can (and will) look ahead in the performance, and this can lead to very high quality matches, i.e. the resulting match comes close to the ideal maximum match (see section 2.5).
Real-time matchers, or score followers as they are commonly called, act in a wholly different context, namely in the performance of `electronic music.' Tape recorders and other electronic equipment have been employed in music from their very invention by composers as Stockhausen and Boulez. The difficulty with this kind of music is that the performer has to adjust his or her performance to the tape, but the tape cannot adjust itself to the performer, and this one-way communication makes performing these works very difficult.
To make the tape more responsive to the performer, the tape was replaced by a synthesizer driven by a computer program, because a tape cannot alter its speed without altering the pitch of the recording. The program in question is called a score follower. It would follow the performer by way of a stored score, and perform its own part accordingly.
Score followers cannot look ahead in the performance (because they cannot look ahead in time), have real-time constraints on the finding of a match, and can therefore not afford a good but slow matching algorithm. Not every note has to be matched, as long as the matcher can still follow the performer. The same thing happens to a person when reading a full score (a score of a whole orchestra) along with the music: there is no time to look at every note, one concentrates on the `important' voices.
From this moment on, we will refer to real-time matchers as score followers, and to non real-time matchers as matchers. In section 3.5 we will look at several examples of both score followers and matchers.
A score can be represented in various ways, and the representation chosen is of great influence on the possible methods of matching and on the quality of the resulting match. In this section I will discuss three possible data structures by which a score could be represented: a tree, a thread and a list.
Lists and trees are common enough data structures, but threads are less often seen. A thread is a special kind of directed graph--digraph for short--, that can be distilled out of a tree. Every data structure has its advantages and its disadvantages, and an advantage can turn into a disadvantage, depending on the demands the matcher has to meet.
For a matcher, the most natural choice of representation would be a tree, because there occurs no loss of information[8]: the definition of a score is given recursively, in the form of a tree. This is the biggest advantage of a tree; the biggest disadvantage is that the structure of a score (and hence the structure of the corresponding tree) can become very complex, so that it would become very time-consuming for a matcher to decide which note follows which.

Figure 3.1: Example Score
Consider the score in figure 3.1. There are two melodies playing simultaneously: one in the upper stave, one in the lower stave. Each melody consists of two phrases[9], so the structure of the tree representation (to be called score tree henceforth) will be as in figure 3.2.
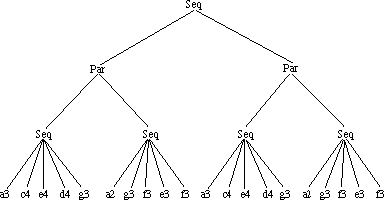
Figure 3.2: Tree representation of the score in figure 3.1
The nodes of the tree are labels of musical objects. `Sequential object' has been abbreviated to `Seq' and likewise `Parallel object' to `Par'. Notes are represented as 4-tuples.
A tree representation of a score can be very complex in the sense that the relations between the notes (which follows which) are difficult to determine. This problem can be solved using a thread. In a thread, the relations between the notes are immediately apparent, but contrary to a tree, there is loss of information. This will be explained below.
The term `thread' comes from `threaded tree', which is a tree with an additional relation on the leaves (nodes without outgoing edges) of the tree. Figure 3.3 gives an example of a threaded tree. A thread is such a relation without the tree.

Figure 3.3: A threaded tree
The trees are always score trees in this case (see section 3.2.1), so a thread is a relation on notes[10] (see chapter 2). If there is an arrow between x and y, it means that `y should be played directly after x.' Below, I will explain what that means by explaining the transformation from tree to thread, but first, I will introduce special kinds of edges in directed graphs. They are not strictly needed, but they make the representation simpler.
In a `conventional' graph, an edge is a connection between two nodes, no more, no less. I will now introduce a different concept: edges that connect two sets of nodes: multiple edges. The concept is introduced purely for the sake of simplicity: multiple edges have almost the same semantics as conventional edges; figure 3.4 illustrates this.
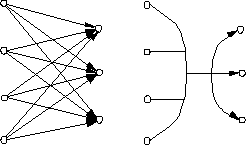
Figure 3.4: Conventional Edges vs. Multiple Edges
When a set of n nodes is to be connected to a set of m nodes, there would be n . m conventional edges needed, while one multiple edge would suffice as well. So, a complete bipartite digraph with n . m conventional edges is equal to one multiple edge with n beginpoints and m endpoints.
There are several special kinds of multiple edges, depending on how many begin- and endpoints they have: joining edges, splitting edges and single edges, which we will define presently.
Definition 3.1 (Multiple edge) Let G be a directed graph (P, L), where P is the set of nodes and L is the set of edges. A multiple edge m in L is a pair (B, E), with B, E != Ø, B, E subsets of P and the intersection of B and E should be empty.
Definition 3.2 (Joining edge) A joining edge is a special case of a mul- tiple edge (B, E), the additional requirement being that |E| = 1.
Definition 3.3 (Splitting edge) A splitting edge is another special case of a multiple edge (B, E), with |B| = 1.
Definition 3.4 (Single edge) A single edge is a multiple edge (B, E), with |E| = 1 and |B| = 1.
Figure 3.5 gives examples of a multiple edge (multiple begin- and endpoints), a joining edge (multiple beginpoints, one endpoint), a splitting edge (one beginpoint, multiple endpoints) and a single edge (one beginpoint, one endpoint).
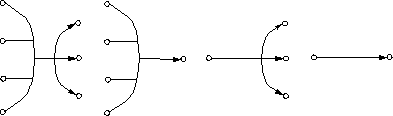
Figure 3.5: From left to right: multiple edge, joining edge, splitting edge and single edge.
A tree, consisting of sequential and parallel objects can easily be transformed to a thread. The transformation [] will be described by way of two pictures and an example. In figures 3.6 and 3.7 the transformation is illustrated. Note that the edges drawn between the sub-threads are not necessarily single edges.
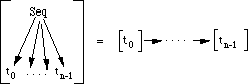
Figure 3.6: Transforming a sequential object to a thread
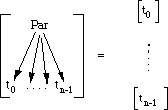
Figure 3.7: Transforming a parallel object to a thread
Ô
Definition 3.5 (Transformation) Let T be a score tree. Then [T] is the thread, resulting from T.
A sequential object is transformed to a thread by transforming all subtrees T0,...Tn-1 to threads and connecting the nodes without outgoing edges of Ti with the nodes without ingoing edges of Ti+1 for all i < n - 1 with one multiple edge.
A thread resulting from the transformation of a parallel object consists merely of all the subthreads resulting from the transformations of all the subtrees of the object. No edges are drawn between them.
Figure 3.8 illustrates the transformation. In a thread, the temporal structure of the score is implicit, contrary to score trees. Even with the limited amount of structured objects allowed in this report (only two), this leads to a loss of information in certain cases.
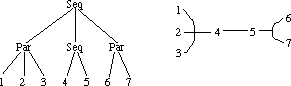
Figure 3.8: A score tree with matching thread
The Loss of information in the transformation from score tree to thread occurs when a parallel object contains another parallel object, or a sequential object contains another sequential object. The trees presented in figure 3.9 are all indistinguishable from the viewpoint of a thread.
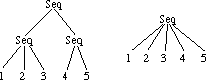
Figure 3.9: Equivalent Score trees
The transformation from score tree to thread being defined, we can
now define an equivalence relation on score trees. By definition, the
transformation [] is bijective on the equivalence
classes.
Ô
Definition 3.6 (Score tree equivalence) Two score trees T0 and T1 are equivalent if [T0] = [T1] ('=' being an equivalence relation on graphs).
Whether a score thread is a suitable representation for a score, depends on whether one would want to treat the elements of an equivalence class differently from one another. Nesting sequential objects could for instance be used to indicate the phrase structure (as in figure 3.2) to provide extra information[11] for the matcher, so if one would want to use that information, a thread would be unsuitable to represent the score.
An important advantage of a thread is that it is very easy to determine the order in which the notes are to be played; in a tree this is more difficult. The reader can easily verify that the first note to be played has no ingoing edges. In the case that a score starts with a chord, there will be several nodes in the thread without in-going edges. This means that in a thread G representing a score (the score thread G), the set of candidates for a match, is the set of all nodes in G without ingoing edges.
The matching process continues analogously to the process employed in the strict matcher (see chapter 4).
The simplest structure to store a score in, is a list. The
transformation from a tree to a list is very straightforward: the
leaves of the tree are taken and ordered on onset times (when two
notes have the same onset time, their order is arbitrary). In this
way, more information than in a thread is lost, because now every
tree that has the same leaves, regardless of how the tree itself
looks, has the same list representation (which we will call score
list). Before looking at the amount of information lost, we will
define the score list. A score list will also be referred to as
note-list (see section 2.4).
Ô
Definition 3.7 (Score list) A Score list is a list of notes x0,...xn-1, such that the following holds:
Like in a thread, the structure of the original score tree is made implicit. When the structure is made explicit again, by transforming the list back to a tree, only the simplest kind of parallel objects can be recognized: notes that have the same onset, so a tree reconstructed out of a score list is always a sequential object containing notes or parallel objects, that can only contain notes. This means that such a tree can at most be three levels deep. Compare the tree in figure 3.10 with the tree in figure 3.2. They represent the same score, but an entirely different temporal structure.
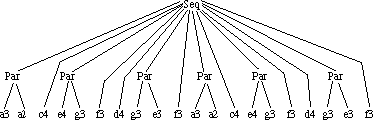
Figure 3.10: A tree representation from a list representation
Musically speaking, the structure of figure 3.2 is to be preferred above the structure of figure 3.10, but a matcher could also perform better on the structure of figure 3.2. A lot of notes that are related to each other (belonging to the same voice, for instance) don't have that relation in figure 3.10, whereas several notes that weren't explicitly related to each other, do have a relation in figure 3.10 (they are to be played at the same time).
A list, when implemented as an array, is very efficient and easy to work with, and hence, the score list representation is mostly used by score followers, because of the time constraints they have to meet.
We would like to be able to have a predicate f on pairs of notes such that f (x, y) = 0 if x (a score note) and y (a performance note) match and f (x, y) = [infinity] if they don't. A predicate that takes two notes and yields a real number we will call a stress measure, the result of such a predicate being the stress between x and y. If the stress between two notes is low (not necessarily equal to 0), they are likely to match, if the stress is high, they are not likely to match.
A stress measure is always a compromise between complexity and accuracy. Score followers often work with a very crude stress measure, while matchers can afford to use a more complex one. The simplest kind of stress measure uses only pitch information. Because we have limited the notes allowed to a subset of the natural numbers[12] the pitch information can easily be used to match score and performance notes, for instance in the following stress measure:
Two notes match if their stress is equal to 0. In certain kinds of music, when played by a good performer (i.e. a performer who doesn't make many errors), this is a surprisingly good way of matching. Almost every score follower uses this stress measure or a stress measure directly derived from it, as does the strict matcher described in chapter 4.
A more sophisticated stress measure would incorporate onset time information. The reader will remember that a score uses symbolic values for onset times, while a performance has its onset times in seconds. To get around the difficulties of the different timing of score and performance, we will look at tempo changes instead of absolute onset times; tempo changes can be computed by comparing inter-onset intervals (the time between two consecutive onsets).
This is in the case of a sequential object. A parallel object has no notion of tempo, so we can't use inter-onset intervals. Instead, we will use a simpler stress measure based on pitch information and context information: suppose score notes x and y are in the same parallel object, and x has been matched to a (a performance note). If y is to be matched to b, b has to have the same pitch as y and `lie sufficiently close to' a, i.e. |onset (b) - onset (a) < n. It has been empirically determined that 100Ôms is a good value for n.
Using timing information in a stress measure boils down to developing some kind of tempo tracker (which is an algorithm that can predict the onset of the next note to be played based on knowledge about the score and notes played in the past), a well-known and difficult problem in music cognition. An introduction to the various approaches to this problem can be found in Desain & Honing (1992), chapter II: Perception.
I will now describe a simple method of tempo tracking that could be used in the new matcher proposed in chapter 6. To the best of my knowledge, there is no way to prove or disprove its suitability other than just trying it out, but it was outside the scope of this report to do so. This method has been described in Vantomme (1995) and should give very good results.
The local tempo of a score note x can be computed as follows:
The function previous returns the previous note in the score, the function matched returns the performance note that was matched with x. It is clear that to determine the local tempo of a note, the note must be matched, and have a predecessor with a match (after all, one note has no tempo). The local tempo is the ratio between score inter-onset time and performance inter-onset time.
Predicting a performance onset from local tempi depends on the validity of the assumption that the tempo of a piece of music changes only very gradually. Luckily, this is so. There are, however, minute variations in tempo that seem to be rather erratic and unpredictable[13]: we can safely ignore them for our matching purposes, but they make all the difference in an expressive performance (Desain & Honing, 1992, pp. 25-40).
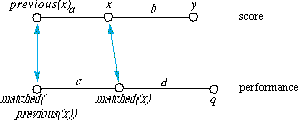
Figure 3.11: Predicting a performance onset from local tempi
Figure 3.11 illustrates the following. Suppose we want to predict the onset of q. Assuming the tempo will not change at all, we have the following equation:
and therefore
or, in terms of onsets:
or, in terms of local tempo:
A stress measure based on this equation could look like this (I actually use this one in an example in chapter 6):
It is not very realistic to assume that the tempo would not change at all; it does so all the time. A more reliable prediction could be made by looking not only at the last local tempo, but at a list of local tempi. One could then make a graph of these local tempi and draw a curve or a line through the points to predict the next performance onset. For instance, one could take the average of all the tempi (figure 3.12) to predict the next local tempo, or one could fit a straight line through the points with the least-squares method (figure 3.13).
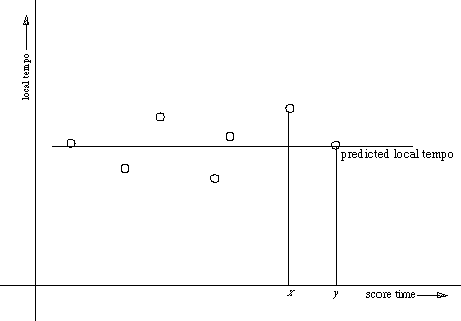
Figure 3.12: Predicting the next onset by taking the average of all local tempi
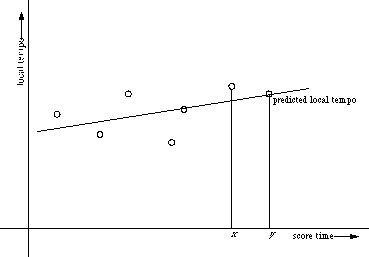
Figure 3.13: Fitting a line to the tempi with the least-squares method
In both figure 3.12 and 3.13 all 6 points drawn have been taken into account in determining the local tempo of y. If another number of points were taken, the lines would of course look different. Vantomme uses a variant of figure 3.13, using 8 local tempi to determine the next local tempo (Vantomme, 1995).
These methods of predicting the next onset are but rough guesses. They are likely to produce an answer that is close to the actual onset, but are not likely to `hit the nail on the head,' because of the minute expressive time differences mentioned earlier. A more complicated algorithm (see Desain & Honing, 1992) might do a better job.
However, a reasonably good guess will serve for most matching purposes. If the stress between say, x and y is higher than the stress between x and z, the match (x, y) is not likely to be a better match than the match (x, z).
The matching problem would be a lot easier to solve if we knew beforehand the performance was flawless. Unfortunately, there are no perfect performers: errors are made all the time. One of the most difficult aspects of performing on stage is dealing with one's own errors. A good performer will manage to cover his or her mistakes so well that the audience either isn't aware of the mistake, or forgives the performer instantly[14].
A key point in all the matchers discussed in this report is that the matchers are without exception very `distrustful' of the performer: if a performance note does not meet the expectations of the matcher, it is considered to be an unintentional error, though it could be intentional and hence no error[15].
I know of one matcher that assumes every `error' in the metrical structure (so intentional pitch `errors' remain errors) to be intentional, and adapts to it through a learning process (this matcher was proposed by Barry Vercoe, see Boulanger, 1990).
Caroline Palmer and Carla van de Sande have conducted a research into errors made in performances (Palmer & van de Sande, 1993), to investigate what musical structures and units are retrieved from memory, organized, and executed in skilled performance. They have drawn conclusions on how a performance is planned from errors and breakdowns resulting in unintended output.
No more about the conclusions drawn from their research will be said here, but among other things, they have made a classification of types of errors, and it is this classification that is of interest to me. It is an adaptation of an error coding scheme used in speech error research with modifications for the musical domain. Figure 3.14 presents an error coding scheme for single-note errors[16]. There are other similar schemes for errors of chord size and note/chord combinations, but in this report I will consider all errors to be single-note errors: other types of errors are combinations of single note errors, and to find the relation between them is outside the scope of this report.
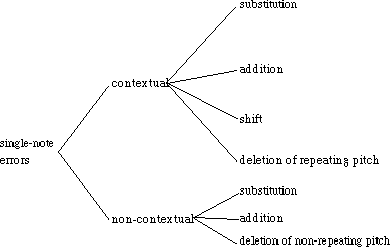
Figure 3.14: Pitch error coding scheme for single-note errors
A distinction has been made between contextual and non-contextual errors. A contextual error is an error resulting from the immediate musical context, as opposed to a non-contextual error, which is due to a technical problem. Contextual errors are important for the research into performance errors, because the planning activities involved in performing come to the surface in the form of these kinds of errors. Non-contextual errors are far less interesting in that respect.
A substitution is an error where a note has been played at the right time, but the wrong pitch, in the case of an addition a note has been played but shouldn't have been and a deletion is the opposite of an addition: a note that should have been played has been left out. Finally, a shift is an error where a note has been played too soon or too late. Palmer and Van de Sande make a distinction between deletion of a repeating pitch and deletion of a non-repeating pitch: in both cases a note has been left out, but when a repeating pitch has been deleted, most likely it was not a technical problem and hence contextual. Analogously, a non-repeating pitch deletion is not likely to be contextual.
A matcher cannot distinguish between contextual and non-contextual errors. It would have to `understand' music to be able to make that distinction, or, to say the least, have a lot more information available than just the score and the performance. Therefore, I will consider all errors to be non-contextual. Two more modifications will be made to the non-contextual part of the scheme in figure 3.14. The error scheme we will use is illustrated in figure 3.15.

Figure 3.15: Error scheme used in this report
We will treat a `Deletion of non repeating pitch' and the contextual error `Deletion of repeating pitch' in exactly the same way: as a deletion, and we will treat a `Substitution' as two errors: an addition and a deletion (if x has been substituted for y, then y has been deleted, and x has been added). The reason for this is that it is difficult to ascertain if an error is a substitution, if the whole performance has not yet been matched to the score: one can, however, make a good guess (see below). The easiest way to recognize substitution errors is to perform a `post-analysis' on non-matched notes when a match has already been made (see chapter 8), but that falls outside the scope of this report.
Another interesting thing about the research of Palmer and Van de Sande is that they used a matcher to facilitate the counting of errors during the experiments the performed. This matcher was proposed by Edward Large (see Large, 1993), and we will refer to it as the tabular matcher. This matcher does handle substitution errors, by `making a good guess' based on heuristics. The matcher is described in chapter 5.
In this section I will give a few examples of the different
classes outlined above. Table 3.1: Classification of different types
of matchersTable 3.1 offers an overview of those examples.A note-list
is a list of notes, ordered by onsets (see section 2.4, it is the
same representation as we use for performances). A window is a part
of the score (or the performance, depending on the matcher) where
candidates for a match are sought. Three out of five matchers only
look forward in the score to get better matching results, Large uses
the largest window possible: the whole piece, and the author of this
report looks both forward and backward--in the performance in this
case.
Ô
|
Author |
Type |
Stress |
Structure |
Window |
|
Dannenberg |
score follower |
pitch |
note-list |
forward |
|
Vantomme |
score follower |
time, pitch |
note-list |
forward |
|
Honing |
matcher |
pitch |
score list |
forward |
|
Large |
matcher |
pitch |
score list |
whole piece |
|
Heijink |
matcher |
pitch, time |
score tree |
around |
The system written by Roger Dannenberg and Hirofumi Mukaino (Dannenberg & Mukaino, 1988) is a three-part system. It consists of a preprocessor, a matcher and an accompanist. I will describe their respective tasks briefly:
This matcher relies solely on pitch information when matching notes. It uses timing information however, to make sure the accompanist is playing in the right tempo, but this information is not used in the matching process itself, rather after that, by the accompanist.
What happens is this: the performance is fed to the preprocessor; the preprocessor detects chords, trills, etc. by using pitch information and feeds an annotated performance to the matcher. From a chord, all notes but one are deleted from the performance by the preprocessor to speed up the matching process. Hence, the matcher only needs a one-dimensional score: a sequential object containing notes.
The preprocessed performance is compared to this note-list and by this comparison the matcher can determine the performer's current position in the score, and an estimation of the performer's tempo. This position is passed to the accompanist, who performs its own part according to the information received from the matcher.
When the performer makes an error, a new matcher is created (so there will be two or more matchers matching at once). The new matcher will proceed in the score, according to the estimated tempo, to see if the performer skips one or more notes; the other (old) matcher remains where the error was made to see if the performer recovers.
Jason Vantomme has written a score follower (Vantomme, 1995), called the Artificial Musician (or AM for short) that uses a radically different approach from all other matchers. Instead of using pitch information as his primary source of information, he uses timing information as his primary source. Only in case of `emergency' he falls back on a pitch matching algorithm.
His score follower predicts a performance onset from a list of local tempi (see section 3.3.1). The performer is allowed to deviate somewhat from this expected onset; this tolerance is referred to as the `window of belief.' This window of belief has no fixed size: when the notes get shorter (actually, when the inter-onset times get shorter), the window length decreases proportionally, and vice versa. This is because "listener tolerance is proportional to decreasing onset time. (...) Though the psychological validity of this method may not be clear, it does provide a useful computational tool" (Vantomme, 1995). It means that a listener will be more aware of notes played out of time in a series of `fast notes' (short inter-onset times) than in a series of `slow notes' (long inter-onset times).
The Artificial Musician only falls back on pitch matching when a performance onset falls outside the window of belief. So, in principle, incorrect pitches can be played throughout the whole piece without the score follower having to use the pitch matcher--provided the wrong pitches are in rhythm. When many incorrect pitches have been recently received and a call to the pitch matcher is required, AM completely fails.
As the comment in the previous paragraph suggests, it is not without risks to follow a score looking at timing information only. After all, human listeners follow the score using both pitch information (or more correctly perhaps: pitch difference information) and timing information in a more or less balanced way (depending on the type of music). However, since an accompaniment part has to be played in rhythm by the score follower, one would expect to get better results from this matcher (if the performer plays in rhythm, that is) than from a matcher using only pitch information to match.
The strict matcher was proposed by Henkjan Honing as part of the POCO system (Honing, 1990 and Desain & Honing, not in print) Its name is due to the fact that the order of the notes in the score list cannot be changed (unless they are to be played at exactly the same time: in that case their order in the performance is allowed to change).
This matcher uses a score window of 3 events (though the size of the window can be changed). An event is either a single note, or several notes to be played at the same time (a parallel object, or chord).
The matcher looks ahead in the score until 3 events are read. Then it takes the first note of the performance and tries to match it to the first note matching in pitch. If, for instance, the performance note matches with a note from the second event, the first event is considered to be a deletion error, because the order of the notes is strict.
If two performance notes are to be matched to notes within the same chord (event), their onsets should not differ more than a user-supplied value called maximum-spread, which defaults to 100Ôms. Two consecutive notes (not belonging to the same chord) should be at least minimum-ioi (ioi being an abbreviation of inter-onset interval) milliseconds apart. This value usually is 80Ôms.
In this way, the matching process continues until either the end of the score, or the end of the performance is reached. The process is fully formalized in chapter *ref*4. As the reader will have observed, this matcher uses pitch information to match, but it also uses context information: it uses its knowledge of the order in which the notes should be played.
The tabular matcher was written by Edward W. Large (he didn't give it a name, but for ease of reference we will call it the tabular matcher) in the course of a research into errors in music performance made by pianists (see section 3.4). The basics of the matcher are described in Large (1993), the details have been made clear to me by the author in private correspondence.
This matcher performs its task in a radically different way from the other matchers discussed in this report. This matcher needs to know the whole performance before a match can be made (so it could not be used as a score follower). Instead, a table is constructed containing points for a particular match combination. Every match gets a number of points[17] depending a complex stress measure based on pitch information.
Before starting the match, the tabular matcher identifies chords in the score and in the performance (like in the previous section, we will refer to them as events). Suppose n is the number of events in the performance, and m is the number of events in the score. The number of rows in the table is n, the number of columns m. The number of points in position (i, j) is the maximum number of points that can be got if performance event i is matched with score event j, and the best possible match is made between the performance notes i + 1,...,n and the score notes j + 1,...,m .
The matcher works backwards, i.e. if the match (i, j) is considered, the table downwards and to the right of that point is already filled. The points for the single match (i, j) are computed and then the highest value from the already constructed table is added to those points.
The use of a table to store previously solved sub-problems is used to lower the computational complexity of an algorithm, in exchange for a higher memory complexity (time/space tradeoff). Without the use of a table, Large's algorithm would have had an exponential complexity, but with the table, it has only a polynomial complexity. This programming technique is also frequently used in parsing algorithms, for instance the Cocke-Kasami-Younger algorithm (Harrison, 1978 and Younger, 1967).
After the whole table has been filled, the matcher can read the optimal match from the table: it starts at position (0, 0), looking for the highest number of points in row 0 and column 0. Suppose that highest value is in position (0, 2). This means that score events 0 and 1 will not be matched (or the highest value would have been (i, 0) or (i, 1), i an arbitrary performance event). The pair (0,Ô2) is then added to the match and the matcher looks in row 3 and column 1 for the highest value, and so on.
The reader will have remarked that instead of matching notes, we are matching events in this case. This means that a performance chord of 3 notes can be matched to a score chord of 5 notes. This match will get a number of points for each note of the performance chord that can be matched to a note in the score chord, and it will get a penalty for every performance note that cannot be matched. This is but a rough outline of the stress measure: the details of this are explained in chapter 5.
The general idea of filling a matrix with values and picking the highest value of them to find the best possible solution is also much used in microbiology, in what is commonly called the DNA homology problem: one wants to know if two nucleic acids have any evolutionary relationship; the problem is very much alike to the score-performance matching problem.
When I began this research, the homology problem was my starting point, but I had to discard the idea as I could not fulfil my assignment this way: I could not use the structure in the score. What is more, I found out that Large had already written an algorithm that solved the problem more or less in this way. Interesting articles on solutions to the homology problem are Dumas & Ninio (1982), Fitch (1966), Goad & Kanehisa (1982) and Sellers (1974). The similarity with Large's solution will be immediately clear.
The structure matcher has some things in common with both the strict and the tabular matcher. Unlike those matchers, however, it represents the score as a score tree (section 3.2.1). It traverses the tree recursively, depth first, and tries to match every score note it encounters.
It considers all the performance notes within the window (explained below) and when more than one performance note could match with the score note, the matcher will try each performance note in turn, ending up with several possible matches between score and performance. The matches are stored in a tree (the match tree) and at the end of the process one match is chosen from the tree (the tree is pruned).
Matching a score note with a performance note is done as follows: the matcher uses a window to look both backward and forward in the performance. Every performance note in the window that has the same pitch as the score note is remembered. Afterwards, the best match is chosen from the tree using timing information.
In the next chapters, I have tried to compare the strict matcher, the tabular matcher and the structure matcher. To do this, they have been specified in the same formalism and their behaviour on a constructed example has been compared as well. The example has been constructed in such a way that every matcher gives a different output on the same input.
The language used in the specification of the matchers is a subset of a specification language called CIP-L as specified in Partsch (1990). This book describes every construct used in the specifications. It would go too far to describe the part of the language used in this report, so please refer to Partsch (1990) for details. For the interested reader: the whole language is described in Bauer et al. (1985).
There is one construct used in some places, which is not described in Partsch (1990) (it is not even part of CIP-L). The construct in question is lambda-abstraction; readers familiar with LISP (Steele, 1990) or the lambda calculus in general (Barendregt, 1984) will recognize the concept.
All data types and `basic' functions on those data types are explained in appendix A. The reason I chose CIP-L to specify the matchers is that I am more or less familiar with the language. It looks a lot like an ordinary programming language, apart from constructs like indeterminate choice, existential and universal quantification (there are more, but these are used in the specifications). In retrospect, it was not such a good choice as it seemed at the time. Because the language looks so much like a programming language, the specifications tend to look more like programs than specifications (though the language is not to blame for that). Maybe Funmath (Van Thienen, 1994) would have been a better choice; I will say more on this subject in chapter 7.
As an example, I will try to match the second measure of the fugue in a-moll for guitar[18] by J. S. Bach. The first two-and-a-half measures are in figure 3.16.

Figure 3.16: Fugue in a-moll for guitar
I have chosen this fugue because of the obvious contrapuntal character of the piece, i.e. there are several melodies sounding together, rather than several chords forming a melody, to show that certain types of errors cannot be dealt with properly without knowledge about the temporal structure. Because of the small size of the example, we can't draw any conclusions about the performance of the matchers in question. To do that, we would have to implement them and test them extensively. However, the example serves very well to show how the matchers perform its task. Moreover, the example has been constructed in such a way that every matcher gives a different output on the same input.
Figure 3.17 shows the score of the second measure of the fugue. Because none of the three matchers uses duration or velocity information of the notes in determining the stress, I have left these attributes out. Note that the onsets of the score have been changed from rational numbers to real numbers, to avoid unnecessary typing problems in the specifications.
parallel(
sequential(
(c3, 0.0)
(f3, 1.0)
(b2, 2.0)
(e3, 3.0))
sequential(
(a2, 0.5)
(a2, 1.0)
(a2, 1.5)
(a2, 2.0)
(g2, 2.5)
(f2, 2.75)
(g2, 3.0)
(e2, 3.5)))
Figure 3.17: Score for the second measure of the fugue in figure 3.16
The performance constructed (constructed, not played) for this example contains three rather serious errors, not likely to occur in a real performance. Furthermore, the tempo is (of course) different from the score. The performance is the following note-list:
(c3, 1.00)
(a2, 1.78)
(f3, 1.81)
(a2, 2.31)
(a2, 2.58)
(b2, 2.60)
(f2, 3.13)
(f2, 3.39)
(e3, 3.81)
(g2, 3.84)
(e2, 4.25)
The first error is that the (a2, 0.5) from the score has been left out in the performance (a deletion error), the second is that the score note (g2, 2.5) has been substituted by (f2, 3.13) in the performance. As we have agreed in section 3.4, we will treat a substitution error as an addition and a deletion error, hence the three errors instead of two.
Because a note-list is not easy to read, the performance is again displayed in figure 3.18, written out as if it were a score. Actually, it is the score of which the performance would be a correct rendering.

Figure 3.18: A `sheet music' representation of the performance of the Bach fugue
The match between the score and the performance is the following list: it is a maximal and maximum match (the list is ordered by score onset).
((c3, 0.0) <-> (c3, 1.00)
(f3, 1.0) <-> (f3, 1.81)
(a2, 1.0) <-> (a2, 1.78)
(a2, 1.5) <-> (a2, 2.31)
(b2, 2.0) <-> (b2, 2.60)
(a2, 2.0) <-> (a2, 2.58)
(f2, 2.75) <-> (f2, 3.39)
(e3, 3.0) <-> (e3, 3.81)
(g2, 3.0) <-> (g2, 3.84)
(e2, 3.5) <-> (e2, 4.25))
Chapter 4 in Postscript format
Chapter 5 in Postscript format
Chapter 6 in Postscript format
The problem of matching a musical score with a performance is a very interesting and complex one. The main reason for this is that the problem itself has no unique definition: there are as many definitions of the problem as there are approaches to the solution of the problem. There is also trouble from a philosophical corner: how much can one demand of a matcher? What I mean is that human beings sometimes have tremendous difficulties in score following (even people with extensive musical training!); can one expect a matcher to do as well or better than human beings on these kinds of `difficult' scores? Because it is not clear what the cause is that we have so much difficulty with some scores, it is not clear what one can hope to expect from a computer.
In this report I have tried to supply a definition of the problem and give an overview of different approaches to the matching problem. I have treated three possible solutions extensively, namely the strict matcher by Henkjan Honing, the tabular matcher by Edward Large and the structure matcher by the author of this report.
We have seen three different score representations: a score tree, where there is no loss of structure information (section 3.2.1), a thread, where some structure information is lost (section 3.2.2) and a score list, where most of the structure information in the score is lost.
A score list is mostly used by score followers, because of the time constraints they have: they cannot afford to lose time in searching through a score tree. A score list is a very simple representation of a score and it suffices in most cases.
It does not suffice in case there are two or more parallel melodies in the score: a score list is unable to represent this kind of structure. A thread, however, can represent this. When a stress measure based on timing information is used in a matcher (or score follower), one would want to be able to represent two parallel melodies: the two melodies should be able to `drift apart', in other words, the should be allowed to have different a different tempo from each other. This is impossible in a score list.
A thread, as we have seen, has its limitations as well. A thread is unable to represent e.g. a sequential object containing two other sequential objects. If one would want to use this kind of information to indicate phrasing structure or something like that, one would have to use a score tree.
Because the definition of a score (section 2.3) is given recursively, a tree can represent the score without any loss of information. The disadvantage of a tree is the complexity. When a tree gets very complex (many nested objects) it is difficult to determine which note follows which.
A matcher, where time constraints are not the issue, would (in principle) perform best on complex scores using a score tree representation. As we have seen in chapter 5, very good results can be got even if a simpler representation is used.
We have tried to compare the strict matcher, the tabular matcher and the structure matcher. Because we have only examined their behaviour on a very small example, we should be very hesitant to draw conclusions on their respective performance and behaviour. Nevertheless, we are able to conclude the following:
The strict matcher was designed to match scores with so-called expert performances: a performance played by an expert. Therefore, its error-handling algorithm is not very good. We have seen that the matcher is not able to cope adequately with errors made in repeating notes of the same pitch.
On the positive side, the matcher is very efficient. It tries to match a performance note only once, so if n is the number of notes in the performance, the time complexity of the strict matcher is O(n). Furthermore, the matcher is incremental, so in principle, it could be used as a score follower.
Contrary to the strict matcher, the tabular matcher can handle errors in a very good way. It was designed to count errors made in performances, so one would expect this matcher to perform well on highly erroneous performances. As we have seen, it has no difficulties with errors made in repeating notes.
The price we have to pay for this excellent error-handling is a (comparatively) high complexity: the algorithm is still polynomial, but instead of O(n) its complexity is O(n3) if the performance and the score are more or less of equal length. The reason for this high complexity is that many single match combinations are computed needlessly (e.g. the first note of the score is compared to the last note of the performance). Unfortunately, there is no way of knowing which single match combinations were not needed until the match has been made. If it were known that the performance was played by an expert, large portions of the table could be left uncomputed.
The tabular matcher is non-incremental. This means that it has to know the whole performance before the match can be made, which makes the matcher unsuitable as a score follower.
The structure matcher is a cross-breed between the strict matcher and the tabular matcher. Depending on the window, it looks more like the one or the other. If the window is very large, the matcher will perform like the tabular matcher, only in exponential time complexity, because of the use of a score tree representation and because the match is also represented as a tree. With a small window, the matcher would look more like the strict matcher, except, of course, that it uses onset information as well as pitch information.
The performance of the structure matcher is hard to judge from the small example we have treated. We have seen that the match tree grew very quickly, mostly because of the large window we chose (4 seconds in total, which is much too large for practical uses). Nevertheless, we can conclude that the structure matcher is much slower than either the strict or the tabular matcher.
It seems as if the structure matcher handles errors at least as well as the tabular matcher, but that would have to be tested on larger performances.
I regret to say that the specifications look more like programs than they should have. Because of this, they are difficult to read and to reason about. The reason for this is for the most part to blame on my inexperience with specifying systems.
In the curriculum of fundamental computer science of the University of Nijmegen, there is (in my opinion) too little occasion to gain experience in this matter. There are courses on the subject, but they are not obligatory. The problem is that in order to finish the studies in four years, one has to make choices about what courses to follow; it is therefore impossible to know something about every subject taught in this university. Unfortunately, some more or less basic courses tend to be missed by a lot of students. In this case, I missed the course about specifying systems.
A second point is that the language itself is not very readable, but that is a matter of taste.
A second gap in the curriculum of computer science is learning how to conduct a research. There are seminars to learn how to do this, but I don't think they live up to their goal. In a seminar, a report is made: in most cases it is a comparison between various methods of solving the same problem. The actual research I conducted was very different of everything I had done so far. In my opinion this should not be the case; certainly not in a graduation assignment.
When I started the research, the plan was to produce an implementation of the algorithm specified in chapter 6. Obviously, this goal has not been reached. The reason I did not reach my goal is that I have encountered many unexpected and non-trivial problems on the way. Of course, this is the natural course of events when researching in a field where there have been not many satisfiable solutions, but I didn't know that (though maybe I could have guessed it). I spent a lot of time without knowing where I was going; I won't say the time was waisted--rather the opposite, I have learned a great deal from it--but six months is so short a time, one cannot afford to waist any.
My point is that I should have been taught how to go about a research like this before the graduation assignment. I am of the opinion that for students of the fundamental line in Computer Science a course on doing research should be obligatory: it would probably raise the standards of a graduation report.
There are lots of improvements that can be made to the three matchers I have described in this report. In this chapter I will give an overview of those possible improvements as well as mention several new possible areas of future research.
The strict matcher uses a window of n events (n a natural number) to look forward in the score. If there are lots of short notes, this window could be too small, or inversely, if there are but few long notes, the window could be too large. These problems could be solved by specifying the length of the window in milliseconds, rather than in events. In this way, the number of events in the window will vary according to the situation.
It would be interesting to see if and how the strict matcher would improve its behaviour by supplying it with a thread representation. In this way, two parallel melodies could be allowed to drift apart, while the complexity doesn't rise very much. The thread representation could also be of use in score followers.
The strict matcher could also be equipped with a more sophisticated stress measure, based on pitch and onset information. This could dramatically improve its error handling. In my opinion, the strict matcher has a very good chance of becoming a very good and very efficient matcher, if a stress measure incorporating time is used, and a thread representation for the score. Very probably, it would not be a very demanding task of rewriting the strict matcher in this way.
To raise the performance of the tabular matcher, one could insert an extra parameter, denoting the `quality' of the performance: with such a parameter, one could ignore parts of the match table and thereby save a lot of time. Perhaps the tabular matcher could also use timing information to limit the entries in the table.
There are a lot of improvements possible on the structure matcher. Firstly, instead of a match tree, one could represent the matches as a graph, i.e. a 'tree' where branches come back together if they arrive at the same point in a match. This would do a lot of good for the time complexity of the structure matcher. Furthermore, some kind of heuristic would be in order to be able to reject branches of the tree at an early stage, based on, for instance, the average stress of that branch.
If the window of the structure matcher could be placed more accurately, preferably on the place where the next performance note is expected (which could be predicted from the score and the tempo at that point), the window could be much smaller, as would be the match tree.
The stress measures for sequential objects outlined in section 3.3 could be refined by using the duration and velocity attributes in case of doubt.
What we do not yet have is a good stress measure for parallel objects. There is no other stress measure in use than the maximum-spread, as used in chapter 4 and 5. The stress measure used in chapter 6 is a variant of this one, but whether it is an improvement is not clear.
It would probably be well worth researching the possibilities for stress measures for parallel objects. Currently, the structure matcher uses only the last note of a parallel object in determining the local tempo of a chord. The reason for this is open to discussion and we should investigate whether there is a better way to time chords: perhaps even using every note in the chord, or finding a way to determine which note in the chord is the most important for the timing.
I also would like to allow more objects: trills and glissandi, for example. Fortunately, the structure matcher's design is such that adding objects presents no great difficulties, provided that each object has its own stress measure (analogously to s-stress and p-stress). Probably, there would have to be a separate next-node function for each object as well: in a trill, the same note can occur several times (trill(a, b) could be performed as a, b, a, b, a, or a, b, a, b, a, b, a, or b, a, b, a, b, a, etc.).
There exists already an implementation of the strict and the tabular matcher. Before any attempt to implement the structure matcher is made, I think it would be well worth the trouble of re-specifying the matcher, preferably in a less programming-language-like language. Funmath (van Thienen, 1994) would probably be a good choice.
With the advent of multi-media and Internet, matchers could be used for a lot more applications than they are used for today. For instance, there exist encyclopedias of musical themes. If one walks around for days singing 'the Blue Danube' without knowing its name, one could look it up in this book. The themes are ordered by the first couple of notes in the melody, transposed to the key of C major; in the case of the Danube it would be 'ccegg'. If one makes a mistake (forgetting the first note for instance) it is very difficult to find the right fragment.
Instead of such a book, a database of musical themes could made, and a user of this database could play a piece of a melody on a keyboard, after which a matcher (like the tabular matcher, for its performance on erroneous performances) looks for the right fragment in the database. This application of a matcher is almost exactly equal to the DNA homology problem (see section 3.5.4).
[TO BE INSERTED]
M. Balaban, Music Structures: A Temporal-Hierarchical Representation for Music, Musikometrika 2 (1989).
H. P. Barendregt, the Lambda Calculus, its Syntax and Semantics, revised edition, Studies in Logic and the Foundations of Mathematics, North Holland, Amsterdam (1984).
F.L. Bauer (et al.), the Munich Project CIP, Volume I: the Wide Spectrum Language CIP-L, Lecture Notes in Computer Science 183, Springer Verlag (1985).
Richard Boulanger, Conducting the MIDI Orchestra, Part 1: Interviews with Max Mathews, Barry Vercoe, and Roger Dannenberg, Computer Music Journal (1990) 14 (2), pp. 34-46.
R.B. Dannenberg, An on-line Algorithm for Real-Time Accompaniment, ICMC Proceedings (1984), pp. 193-198.
R.B. Dannenberg and B. Mont-Reynaud, Following an Improvisation in Real-Time, ICMC Proceedings (1987), pp. 241-248.
Roger Dannenberg and Hirofumi Mukaino, New Techniques for Enhanced Quality of Computer Accompaniment, ICMC Proceedings (1988).
Peter Desain and Henkjan Honing, POCO II Documentation, supplied with the LISP program POCO II, not in print.
Peter Desain and Henkjan Honing, Music, Mind and Machine, Studies in Computer Music, Music Cognition and Artificial Intelligence, Thesis Publishers, Amsterdam (1992).
Jean-Pierre Dumas and Jacques Ninio, Efficient Algorithms for Folding and Comparing Nucleic Acid Sequences, Nucleic Acids Research (1982) 10 (1), pp. 197-205.
Walter M. Fitch, An Improved Method of Testing for Evolutionary Homology, Journal of Molecular Biology (1966) 16, pp. 9-16.
Walter B. Goad and Minoru I. Kanehisa, Pattern Recognition in Nucleic Acid Sequences I. A General Method for Finding Local Homologies and Symmetries, Nucleic Acids Research (1982) 10 (1), pp.Ô247-262.
M. A. Harrison, Introduction to Formal Language Theory, Addison-Wesley (1978).
Henkjan Honing, POCO: an Environment for Analysing, Modifying, and Generating Expression in Music, ICMC Proceedings (1990), pp.Ô364-368.
Sonya E. Keene, Object-Oriented Programming in Common LISP, Addison-Wesley (1989).
Edward W. Large, Dynamic Programming for the Analysis of Serial Behaviors, Behavior Research Methods, Instruments & Computers (1993) 25 (2), pp. 238-241.
Nijmegen Institute for Cognition and Information, Research Program, Project Planning and Project Summaries, not published.
Caroline Palmer and Carla van de Sande, Units of Knowledge in Music Performance, Journal of Experimental Psychology: Learning, Memory and Cognition (1993) 19 (2), pp. 457-470.
Helmut A. Partsch, Specification and Tranformation of Programs: a Formal Approach to Software Development, Texts and Monographs in Computer Science, Springer-Verlag (1990).
Peter H. Sellers, On the Theory and Computation of Evolutionary Distances, SIAM Journal of Applied Mathematics (1974) 26 (4), pp. 787-793.
Guy L. Steele, Common LISP, the Language, Second Edition, Digital Press (1990).
Huub van Thienen, It's About Time: using Funmath for the specification and analysis of discrete dynamic systems, Nijmegen (1994).
Jason D. Vantomme, Score Following by Temporal Pattern, Computer Music Journal (1995) 19 (3), pp. 50-59.
Theo Willemze, Algemene Muziekleer (`General Music Theory'), Aula Paperbacks 155 (1987).
D. H. Younger, Recognition and Parsing of Context-free Languages in Time , Information and Control (1967) 10, pp. 189-208.
{kind=link}
{kind=link}
{kind=link}